Unlocking Enterprise Knowledge Access with AI: Building a RAG Pipeline Using Boomi
In today’s fast-paced digital world, accessing the right information at the right time is critical for decision-making. However, enterprise environments often face fragmented data landscapes and growing volumes of unstructured content. While large language models (LLMs) like OpenAI’s ChatGPT have unlocked new possibilities in automated text generation, their effectiveness often diminishes when they lack access to company-specific knowledge.
To address this gap, I recently completed a research and development project centered around a Retrieval-Augmented Generation (RAG) pipeline that leverages Boomi as an integration platform. The goal is to enable context-aware, accurate, and interactive responses from LLMs by dynamically connecting them to real-time enterprise data.
The Challenge
Public LLMs are powerful but isolated. They struggle with outdated knowledge and can’t access confidential enterprise information without risk of data leakage or compliance violations. Traditional fine-tuning is costly and static. Enterprises need a secure, scalable way to make business-critical knowledge accessible to LLMs without compromising privacy or governance.
At Apps Associates, this challenge wasn’t just theoretical. Our team needed to solve it because we wanted to enable employees to ask natural-language questions in a communication pipeline like Microsoft Teams and instantly receive accurate answers drawn from internal systems and documents. Without a solution, employees would continue spending valuable time searching through repositories, risking errors, and losing efficiency.
Our Approach: RAG + Boomi + Teams
Our RAG pipeline is designed as an orchestrated, event-driven system that connects end users, enterprise data sources, and AI models into a seamless, secure workflow. The diagram below illustrates the architecture we implemented:
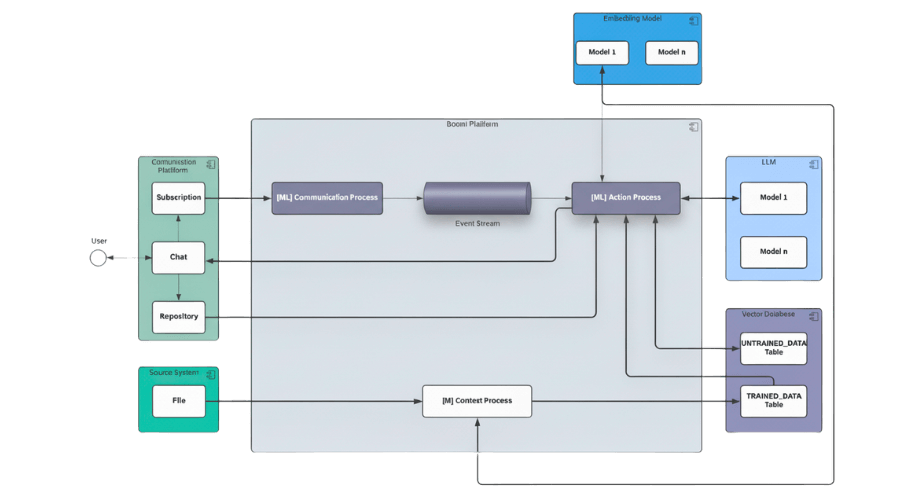
Step-by-Step Architecture Walkthrough:
- User Interaction via Communication Platform: End users interact with the system through a communication platform in our case, Microsoft Teams.
-
- Chat: The main entry point where users submit questions or requests
- Subscription: Keeps the system updated with incoming messages in near real-time
- Repository: Any files shared by the user
-
- Source System Integration: External Source Systems (e.g. document repositories, file storage) feed data into the pipeline. Files are sent into Boomi for further processing.
- [M] Context Process: This process prepares enterprise knowledge for retrieval:
-
- Extracts and processes text from files and repositories
- Generates embeddings using Amazon Titan Embedding (AWS Bedrock)
- Stores embeddings in the Vector Database (Oracle) in two tables:
- TRAINED_DATA: Validated, ready-to-use knowledge
- UNTRAINED_DATA: Newly ingested, pending validation
-
- [ML] Communication Process: Handles all incoming user messages from the communication platform and pushes them into the Event Stream for asynchronous processing.
- Event Stream: Provides a reliable, decoupled message-handling infrastructure ensuring scalability and event-driven orchestration.
- [ML] Action Process: The following steps are part of the RAG-Pipeline processing:
- Uses the Embedding Model (AWS Bedrock) for converting the user request into semantic vectors
- Retrieves relevant context from the Vector Database by semantic search
- Calls the LLM (AWS Bedrock) with the retrieved enterprise-specific context to generate enriched responses
- Sends results back to the user via Microsoft Teams
Key Innovations
- End-to-end orchestration in Boomi: From incoming Teams messages to retrieving context from the Vector DB and sending LLM responses back – all modeled as visual processes.
- Secure knowledge integration: No sensitive data leaves the ecosystem. All processing happens through governed APIs, compliant with GDPR.
- Automated feedback loop: Both users and LLMs assess answer quality, enabling ongoing optimization.)
How This RAG Solution Stands Out
While RAG architectures are becoming increasingly common, most implementations or solutions rely on isolated Python backends or single-purpose cloud functions that are difficult to scale, govern, and maintain. The solution we developed at Apps Associates offers several distinct advantages:
- Full Integration into Enterprise Systems: Unlike typical RAG setups that operate outside existing IT landscapes, our Boomi-based pipeline integrates seamlessly with enterprise platforms such as Microsoft Teams, Oracle OCI, and AWS Bedrock. This allows users to interact with AI directly in their daily workspace, no additional tools or interfaces required.
- Low-Code Orchestration and Rapid Adaptability: With Boomi’s visual, low-code environment, process flows can be built, adjusted, and extended quickly without the need for complex backend development. This shortens deployment cycles and enables agile adaptation to new use cases or data sources.
- Security and Compliance by Design: All integrations run through Boomi’s governed environment, ensuring that data remains within the enterprise ecosystem. This eliminates “Shadow AI” risks and guarantees GDPR compliance, access control, and full auditability.
- Scalability and Reusability: The modular process design allows components such as context retrieval, embedding generation, or LLM response handling to be reused across departments or projects. Through Boomi’s Event Stream, asynchronous message processing ensures scalability and fault tolerance.
- Flexibility Through Multi-Technology Integration: The architecture is deliberately technology-agnostic. It supports a variety of embedding models, vector databases, and LLM providers, enabling enterprises to switch or expand components without redesigning the entire system. Whether using AWS Bedrock, OpenAI, or other vector engines, the Boomi integration layer keeps the setup interoperable and future-proof.
- Automated Evaluation and Continuous Improvement: Built-in feedback loops from both end users and LLMs enable automated evaluation and continuous optimization of responses. This allows the system to improve answer quality over time without costly model retraining.
Results
A comparative evaluation showed that RAG-enhanced responses significantly outperformed baseline LLM answers in terms of accuracy, coherence, and user satisfaction.
Additionally, this solution demonstrates how Boomi’s low-code capabilities can be extended for advanced AI use cases, turning integration flows into intelligent, context-aware assistants.
This RAG pipeline combines the strengths of Boomi’s integration capabilities with the intelligence of modern LLMs—delivering a secure, flexible, and enterprise-ready solution that goes far beyond the limitations of traditional RAG prototypes.
What This Means for Enterprises
With this approach, organizations can build domain-specific AI assistants that:
- Tap into structured and unstructured internal knowledge
- Provide compliant, auditable responses
- Scale across departments and use cases
- Reduce dependency on external SaaS AI tools (avoiding “Shadow AI”)
Looking Ahead
This project lays the foundation for future AI-powered enterprise solutions. Next steps may include:
- Auto-ingestion of new documents into the vector database
- Advanced prompt engineering for multilingual support
- Extension to voice-activated assistants or web chat
