How to stream data from PostgreSQL to Apache Kafka (and back!)
In today’s world, data is stored across various systems and databases. The process of transferring data from one system to another is known as a data pipeline. These pipelines play a crucial role in enabling the flow of information between an organization’s operational and analytical systems. When it comes to scenarios that require features like “write once, read many” or maintaining the guaranteed order of messages, Apache Kafka stands out as a popular and reliable choice.
In this blog post, we’ll guide you through an exciting journey: streaming data from a PostgreSQL database into Apache Kafka, performing transformations with Flink, and then streaming the data back into the database. Let’s dive in!
Let’s dive directly into it.
These are the components involved:
- A PostgreSQL database
- Apache Kafka
- Kafka Connect with Debezium PostgreSQL Connector and Confluents JDBC Connector
- Confluent Control Center
- Apache Flink
With these components in place, the high-level architecture looks something like this:
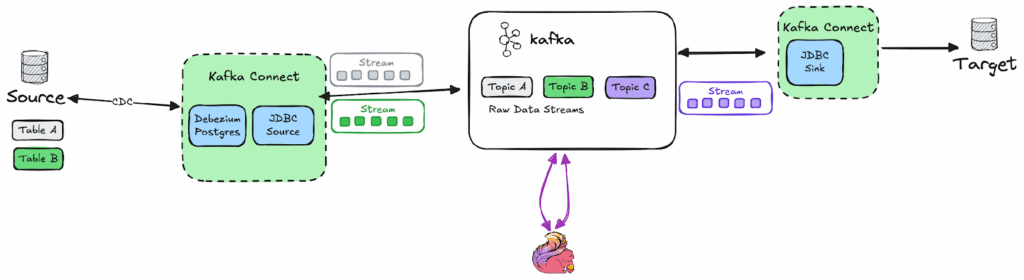
Extracting data from PostgreSQL
The first step in this process is to extract the data from the PostgreSQL database. To accomplish this, we will configure 2 connectors:
- Confluents JDBC Connector
- Debeziums PostgreSQL Connector
At a high level, both of these connectors work towards the same goal. We’ll dig into the specific details later in this post.
Disclaimer:
For this demo we rely on a single broker Kafka cluster, but for a production deployment at least 3 brokers are recommended.
Using Kafka Connect to Extract Data
Kafka Connect provides a no-code way to integrate external systems like databases, object storage, or queues with Apache Kafka.
A Kafka Connect cluster consists of several components:
- A connector instance, which defines the interaction between Kafka Connect and your external source
- A converter, which handles the serialization and deserialization of data.
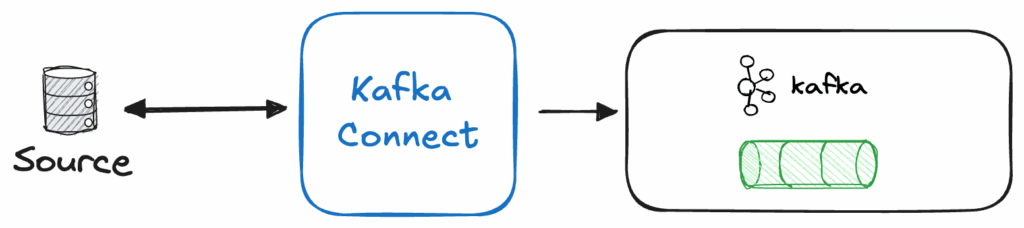
Kafka Connect can be configured easily using a REST API or configuration files, as shown in the snippets below:

As we’ve set the basic let’s go ahead and stream our data from PostgreSQL.
Preparing PostgreSQL for Data Transfer
As we prepare the PostgreSQL for our data transfer, there are a few preparations that must be done.
Before getting started, make sure to:
- Set the wal_level Parameter to “logical”
- Add a new user (or assign to an existing user) with the replication role granted
- ALTER USER $username WITH REPLICATION;
- (Optional: create some test data )
- We use some adopted examples from here https://github.com/morenoh149/postgresDBSamples/blob/master/chinook-1.4/Chinook_PostgreSql_utf8.sql
Kafka Connect – Part 1
Now that the PostgreSQL side is taken care of, let’s move on to Kafka Connect. The first step is to install the necessary plugins in the Kafka Connect runtime.
Apps Associates recommends using the Confluent Kafka Connect image, as mentioned above, so that plugins can be easily installed within the confluent-hub utility.

Alternatively, you may create a custom Docker image, as shown below:

Configuring Kafka Connectors
To configure the connectors, we make use of the Kafka Connect Rest API mentioned above. We will configure two source and one sink connector.
The first connector we use to get data from PostgreSQL is the JDBCSourceConnector.
This connector reads data from the Customer table and writes it to the Kafka topic pg.jdbc.Customer.
A few notes for a successful Kafka connection:
- Connector.class: needs to be set correctly; if misspelled or the class is not available, the connector will fail
- Mode: defines how the connector detects new or updated rows—timestamp+incrementing is the most accurate option.
- Incrementing column.name: The name of the strictly incrementing column to use to detect new rows
- Timestamp.column.name: Comma-separated list of one or more timestamp columns to detect new or modified rows using the COALESCE SQL function
- validate ..non.null: disable not null checks for timestamp and ID columns
Another connector we use to read PostgreSQL table data is Debezium PostgreSQL Connector.
This connector uses logical decoding to stream changes from the Artist table to the Kafka topic cdc.public.Artist.


A few notes for a successful Kafka Connection:
- Name: choose a name of your choice
- Connector.class: needs to be set correctly; if misspelled or the class is not available, the connector will fail
- Plugin.name: name of the logical decoding plugin on PostgreSQL side (https://debezium.io/documentation/reference/stable/connectors/postgresql.html#postgresql-property-plugin-name )
Query the data in Flink
As we now have our data in Kafka, we can access it with Flink.
First, we create a table in Flink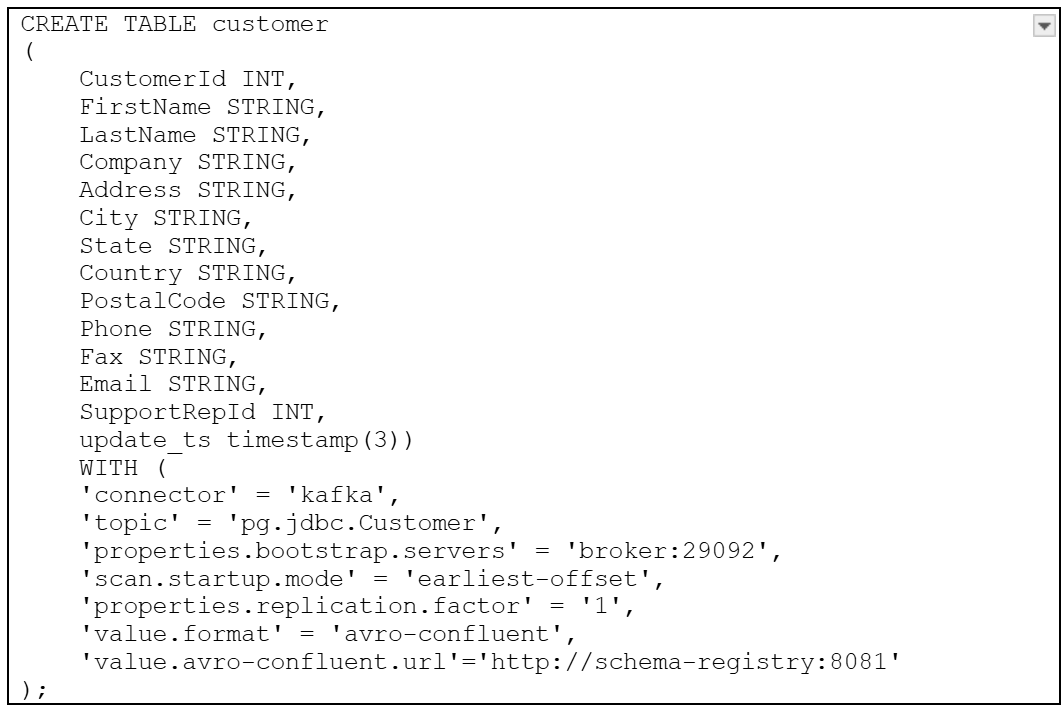
Notes for a successful Flink data table creation:
- Connector: specify the connector to use, as we like to connect to Kafka, we use the kafka one
- Topic: the topic we like to use, CDC. public.Customer, in our case,
- Properties bootstrap. servers: kafka bootstrap server hostname and port
- Scan.startup.mode: the offset to start with, earliest-offset to get all the data in the topic
- Value.format: avro-confluent
Now we create a table demo that will be populated from the customer table created earlier.

And now populate our created table with data from the customer table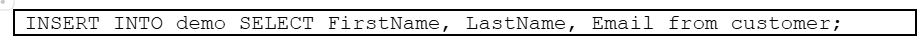
So we end up with 2 Flink tables:

The customer table is a full representation of the customer topic.
Demo table contains FirstName, LastName, and Email from the customer topic.

Figure 1Customer table in Flink

Figure 2 demo table in Flink
Sending data back to PostgreSQL
Now that we have completed all of these steps, the final step is to send our data back to PostgreSQL.
In order to do this, we must create a connector with the following:

This creates a new table in PostgreSQL and populates it with the transformed data from the pg-sink topic.
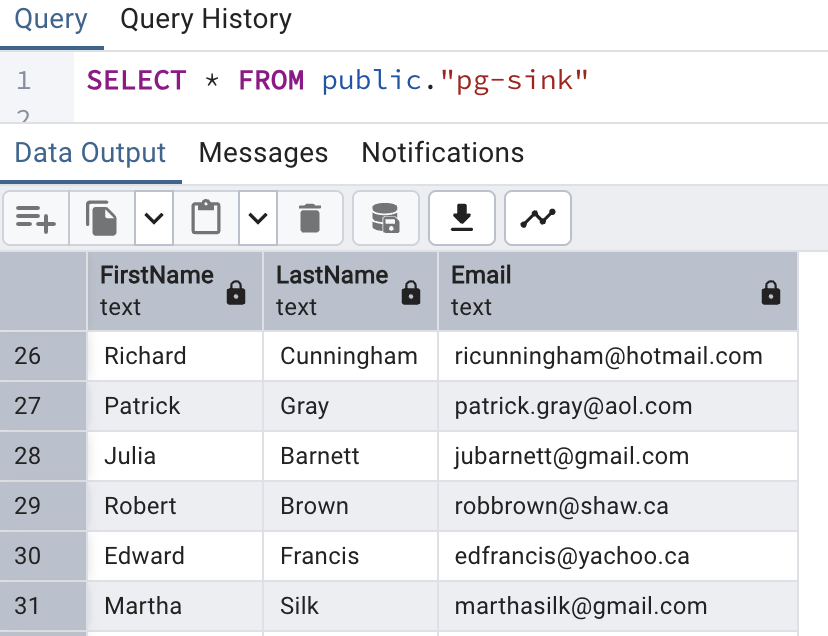
In this article, we have successfully demonstrated a complete data streaming pipeline. You have seen how to stream data from a PostgreSQL database into Apache Kafka, apply basic yet powerful transformations using Flink SQL, and subsequently stream the processed data back into the database. This process illustrates a robust and scalable method for real-time data integration and manipulation. We encourage you to build upon this foundation and explore the more advanced capabilities of these powerful open-source technologies in your own data architectures.
Stay connected with Apps Associates for more useful content on data migration!
