Real-Time Analytics on Databricks: When decisions can’t wait for Dashboards
An end-to-end view of Data, Analytics, and AI on a unified Lakehouse—built for feeds that arrive in seconds, not overnight batches.
The two clocks
Picture a busy operations week. Work orders are opening and closing. Inventory is moving. A line goes down somewhere and service tickets spike. On the shop floor and in the ERP, those events are happening now.

Meanwhile, another clock is ticking—the analytics clock. If your pipeline only reconciles once a day, leadership is not debating what to do next; they are debating which stale number to trust. In a fast-moving environment, delay is not just inconvenient. It is missed recovery time, slower escalation, and risk that compounds.
Why batch reporting breaks under pressure
Supply chain and ERP landscapes generate a continuous stream of facts: work orders, inventory movements, procurement transactions, downtime events. Many organizations still land that reality through batch extracts and scheduled ETL—fine for monthly closes, painful for operational judgment.
That gap shows up as:
- Delayed visibility: downtime and inventory shifts surface hours later.
- Reconciliation churn: ERP truth and analytics layers drift until someone runs a full compare.
- Pipeline dependency: one delayed job skews every downstream report.
- Late anomaly detection: SLA breaches and shortages are noticed after the window to respond.
- Cost of full refreshes: recomputing everything burns compute and time.
The underlying issue is architectural: when ingestion and serving are stitched from separate silos, real-time operations outrun the story your data tells.
Enter Databricks: one platform for streaming, analytics, and AI
Databricks brings data engineering, analytics, and machine learning onto a unified platform centered on Apache Spark—extended with governance, collaboration, and cloud-scale operations. For near-real-time workloads, Apache Spark Structured Streaming matters: it consumes live feeds from Kafka, Azure Event Hubs, Amazon Kinesis, or IoT pipelines, typically as micro-batches within seconds, so dashboards and downstream logic can track what is happening—not only what happened yesterday.
Lakehouse: end the false choice between lake and warehouse
Classic architectures split raw lake storage from curated warehouse analytics. Data copied back and forth before anyone asks a question. In streaming scenarios, that friction is expensive.
The Lakehouse model merges those worlds on open storage with warehouse-grade reliability. Delta Lake adds ACID transactions and concurrency controls so the same datasets can power live dashboards, governed analytics, ML features, and audits—without maintaining duplicate truths.
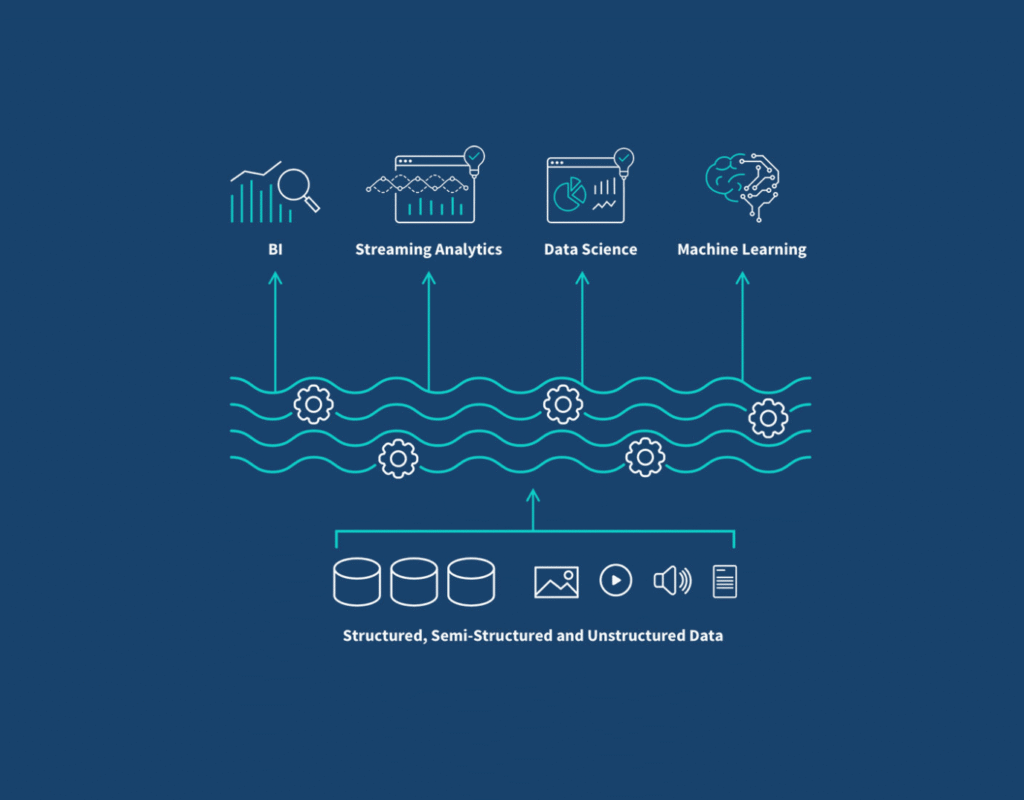
A journey through the solution
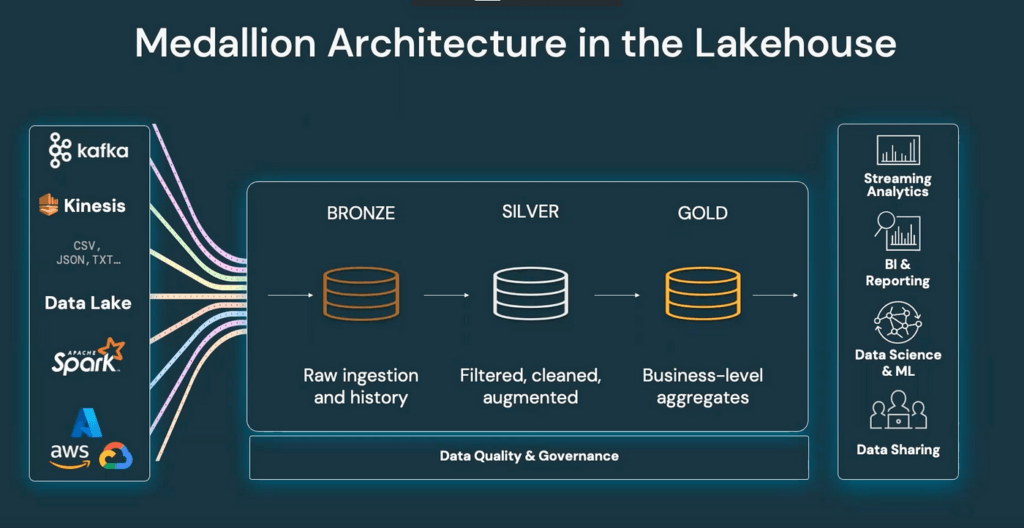
1. Medallion: shape speed without losing control
Bronze holds raw or minimally processed events—replayable history. Silver cleanses, conforms, and joins business rules. Gold delivers curated aggregates and dimensions tuned for BI and ML. Each layer can advance as new events arrive, replacing manual triggers and oversized batch windows.
| Bronze layer (raw) | Silver layer (refined) | Gold layer (business-ready) |
| Streams and batches land from Event Hubs, Kafka, IoT, APIs, and similar sources. Data is preserved for replay and lineage. | Cleansed, enriched, conformed—schema evolution handled with quality gates so downstream consumers see trustworthy records. | Aggregates and curated entities optimized for dashboards, reporting, and ML features—reflecting the latest state. |
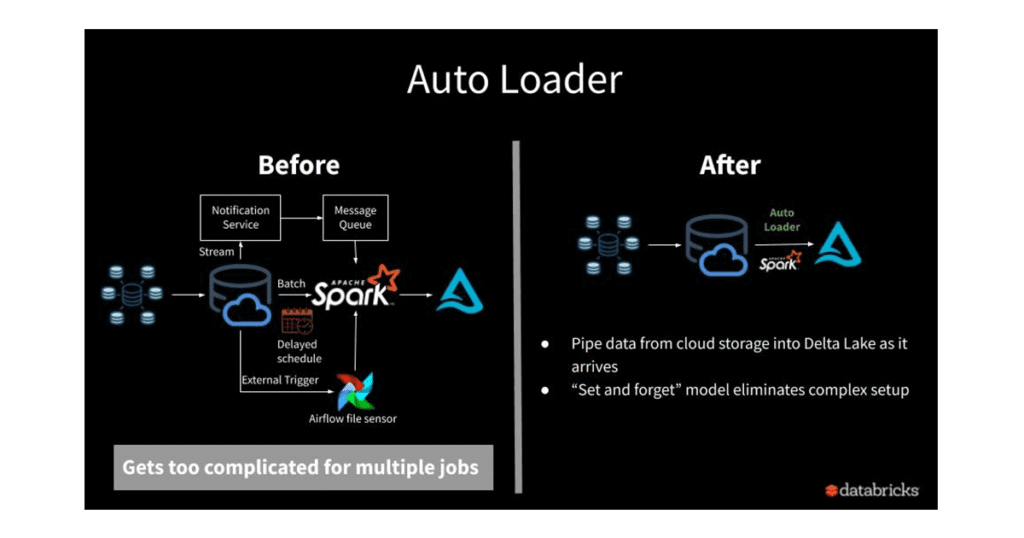
2. Ingest: meet the feed where it lives
Unified ingestion pulls batch and streaming sources—ERP exports, IoT, APIs, messaging—into one pipeline discipline. For files landing in cloud storage, Auto Loader incrementally detects new objects, tracks progress in checkpoints for scalable near-real-time loads, infers and evolves schema, and quarantines bad rows instead of failing silent gaps—often the backbone of Bronze in a medallion design.
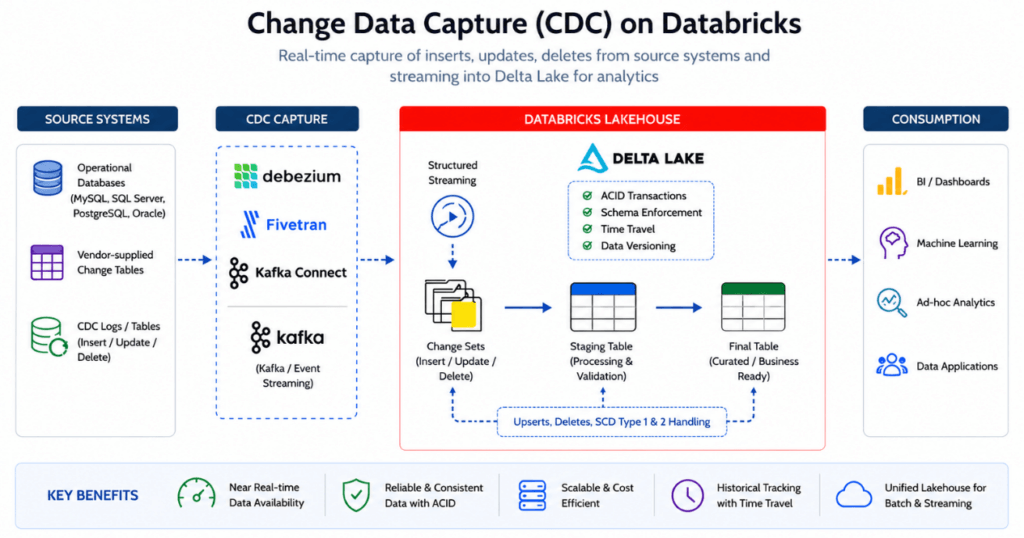
3. CDC: keep the Lakehouse in step with systems of record
data from ETL systems and change tables is ingested into Databricks Delta for scalable real-time processing. Using Structured Streaming, incremental inserts, updates, and deletes are processed through staging layers and merged into curated tables using SCD Type patterns, enabling efficient, reliable, and near real-time analytics in the Databricks Lakehouse platform.
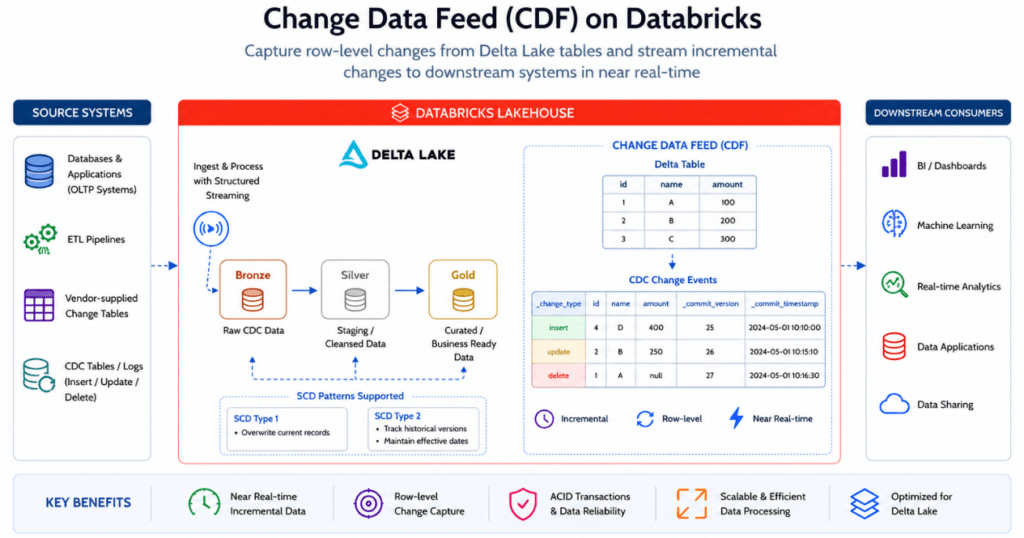
4. Incremental truth inside Delta: Change Data Feed
Change Data Feed (CDF) in Delta Lake captures row-level inserts, updates, and deletes from Delta tables, enabling efficient incremental data processing within Databricks. Using Structured Streaming and Medallion Architecture, downstream Bronze, Silver, and Gold layers can process only changed records instead of full table scans, improving scalability, performance, and near real-time analytics while supporting SCD Type 1 and Type 2 patterns.
5. Unity Catalog: Centralized Governance for the Lakehouse
Unity Catalog provides centralized governance and fine-grained access control across Databricks workspaces, enabling secure management of data, AI models, notebooks, and pipelines with unified metadata, lineage tracking, auditing, and compliance support within the Lakehouse platform.
6. Automate the pipeline: Delta Live Tables
DLT expresses transformations declaratively—expectations for quality, modular stages, checkpointing, and handling late data—so streaming maintenance is operational, not artisanal.
7. Serve fast: SQL, BI, and operational metrics
Databricks SQL and connected BI tools refresh as events land. Photon and caching help interactive workloads keep pace with concurrent users asking ad hoc questions on fresh data.
8. Close the loop with AI: score events as they arrive
ML becomes part of the same flow: models score live events—fraud signals, demand shifts, recommendations—with MLflow supporting versioning and safer promotion as patterns drift.
9. Trust at scale: governance and monitoring
Unity Catalog centralizes access, lineage, and compliance posture. Monitoring—integrated with your observability stack—surfaces lag, backlog, and failures before executives see wrong tiles.
What changes for the business
- Operational visibility as events occur—not after the shift ends.
- Incremental processing instead of endless full reloads.
- Stronger consistency between ERP and analytics because change streams drive the Lakehouse.
- Earlier detection of anomalies and SLA risk with actionable alerting.
- More resilient automation (DLT checkpoints) and leaner compute when only deltas flow forward.
Eight principles teams lean on in production
- Design modular pipelines (ingest → transform → publish) with DLT where it fits.
- Tune streaming triggers for latency vs cost; validate under realistic load with Photon and autoscaling.
- Enforce quality early—bad data propagates faster in streaming systems.
- Monitor continuously (jobs, clusters, throughput); alert before users notice.
- Watch continuous-workload cost (serverless, policies, budgets).
- Automate governance with Unity Catalog from the start.
- Version notebooks, DLT logic, and ML artifacts (Git + MLflow discipline).
- Maintain Delta health (optimize, Z-order where helpful, vacuum policy aligned to retention).
Closing
Real-time analytics on Databricks is less about a single product feature and more about an end-to-end pattern: streaming and batch on one Lakehouse, Delta for reliability, CDC and CDF for incremental truth, medallion layers for clarity, and ML alongside BI so the platform responds at the speed the business runs.
About this article
This story-driven version is intended for publication without customer-specific names, systems, or identifiers. Add or adjust an author bio here if you publish under your byline.
