Using Machine Learning in Oracle Analytics Cloud to Predict HR Attrition
Artificial Intelligence (AI) and Machine Learning (ML) have become popular mainstream topics. You no doubt have read about them or seen programs about them. Typically, they are presented as very complex topics that require specialized computer processing and large teams of highly experienced data scientists. This was true for many years but it is beginning to change and Oracle is at the forefront of this change. Oracle has built machine learning capabilities directly into its Cloud BI platform, Oracle Analytics Cloud (OAC), thereby making functionality like ML and predictive analytics available to regular business analysts (BAs). BAs who are willing to explore this new functionality will find a broad array of ML capabilities that don’t require an extensive background in ML or data science. They will be able to interact with and analyze data in ways they previously have not done and they will be able to add a whole new level of analytical value to their organization – enabling the data-driven decision making so many organizations are pursuing. This functionality is part of the Data Visualization component of OAC and is natively available without any special licensing. In this post, I will show you how to use the machine learning capabilities in Oracle Analytics Cloud to predict HR attrition. It is easy to use and requires no writing of computer code but here are some quick points to know before we begin:
- Custom ML scripts are supported for practitioners who are more advanced
- Oracle also has a fully robust ML and data science platform for data scientists and large-scale ML projects
First a brief primer on machine learning. Two of the major types of machine learning are supervised learning and unsupervised learning. In supervised learning, there is already a data set with the desired label or value. This “labeled” data set is used to train a model. Once the model has been trained, it can be applied to other, unlabeled data sets to predict the desired label or value. In unsupervised learning, there is no labeled data set. The data set is unlabeled and the machine learning algorithm is used to find patterns in the unlabeled data (also known as clustering). Today’s exercise is an example of supervised learning as we will start with a labeled data set to train the model.
So let’s get started. We will use a labeled HR attrition data set freely available from Kaggle:
https://www.kaggle.com/pavansubhasht/ibm-hr-analytics-attrition-dataset
We will upload this data set to Oracle Analytics Cloud.
Step 1: Upload Labeled Training Data Set to OAC
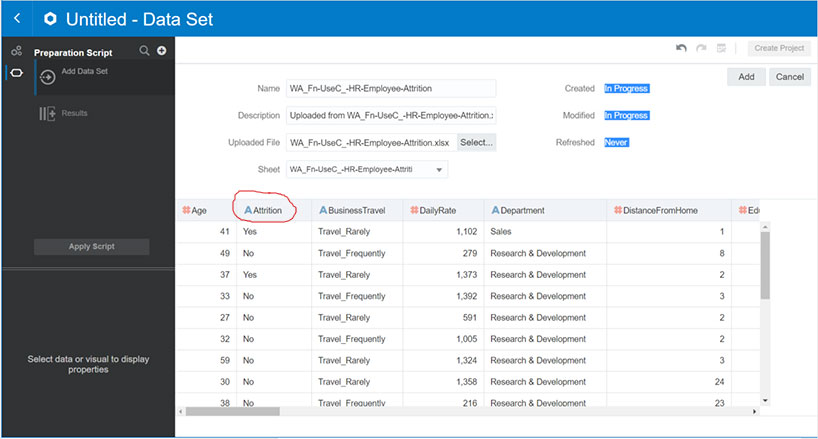
The second column contains the value for attrition. This is our labeled training data set.
The next step is to create a data flow where we will use this data set to train the model. When we create the data flow, we will select the type of machine learning algorithm that we want to use.
Oracle provides a variety of machine learning algorithms covering both supervised learning (e.g. classification) and unsupervised learning (e.g. clustering). For our process, we will be classifying data in one of two ways: Yes or No for attrition prediction. Therefore, we will use the “Naïve Bayes binary classification” algorithm.
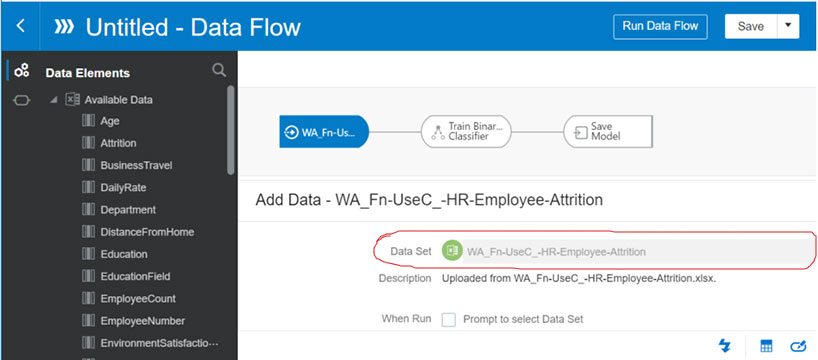
In creating the data flow, the first thing we will do is add our labeled training dataset.
Step 2: Create Data Flow – Add Labeled Training Data Set
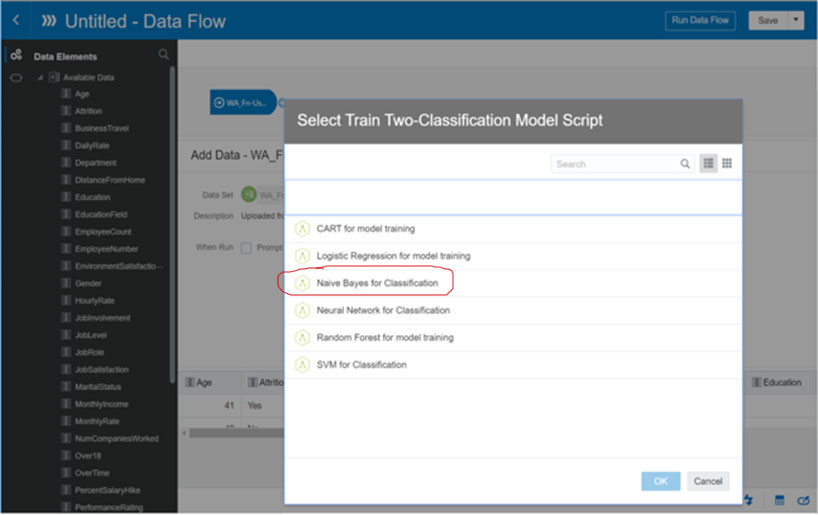
Next we will select the machine learning algorithm to be used to predict attrition. We will be using Naïve Bayes binary classification.
Step 3: Create Data Flow – Select Machine Learning Algorithm
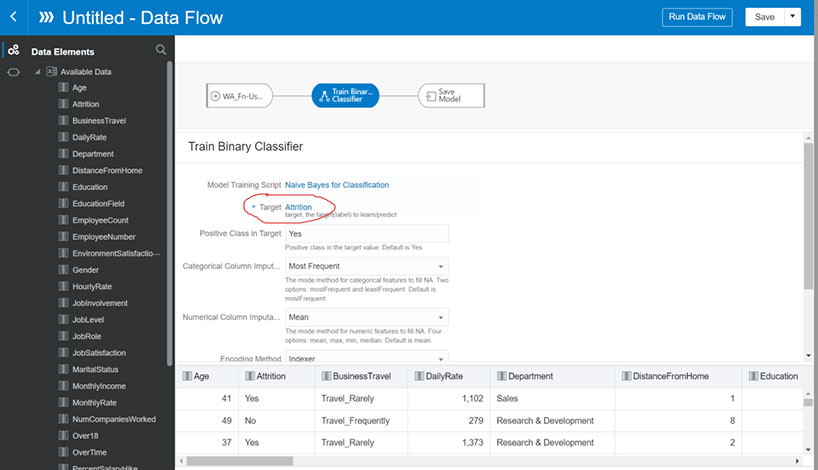
After choosing the algorithm, we need to designate the target – which in this case is “Attrition”.
Step 4: Create Data Flow – Designate Target for Prediction
When this data flow is executed it will create a training model. In the next step we give the training model a name.
Step 5: Create Data Flow – Give the Training Model a Name
Now we need to save the data flow and then execute it to “train the model”. The model is created by successful execution of the data flow.
Step 6: Save and Execute the Data Flow to Create and Train the Model
Now we have a trained machine learning model. Let’s take a look at what is called the confusion matrix to get a sense of the quality of the trained model.
Step 7: Review the Quality of the Model
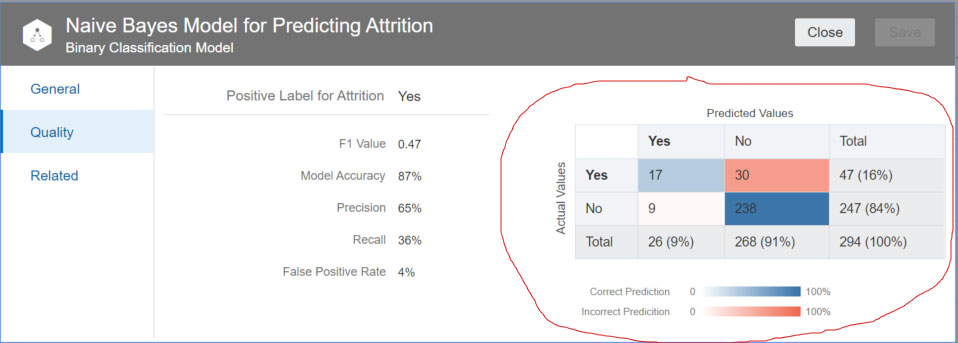
The overall model accuracy is 87% – calculated as (238+17)/294. Precision is 65% – calculated as 17/(17+9). Recall is 36% – calculated as 17/(17+30).
We will now upload a different file that does not have attrition designated against which we will apply the model that we created.
Step 8: Upload Unlabeled Data Set

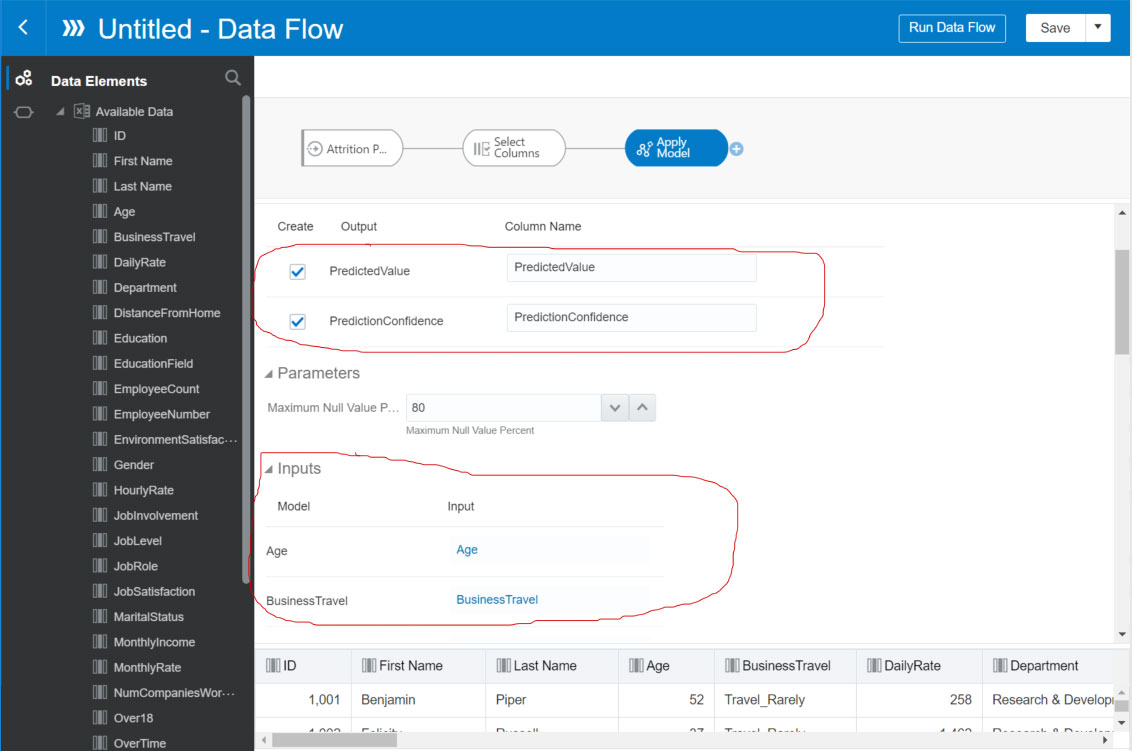
Now we just need to create a data flow to apply the model we created to the unlabeled data set that we just uploaded. A couple things to remember when creating the dataflow to apply the model:
- The unlabeled dataset that is uploaded, against which the model will be applied, must have the same columns as the model
- Give the column that will hold the predicted value a name that is easy to remember
- Review the columns on the input dataset to make sure they have been matched up correctly with columns from the model
Step 9: Create Data Flow to Apply the Model – Name the Output Column and Confirm Inputs
Lastly we will give the output file a name, save the dataflow and execute it to apply the trained model to the unlabeled dataset.
Step 10: Save and Execute the Data Flow to Apply the Model to the Unlabeled Data Set
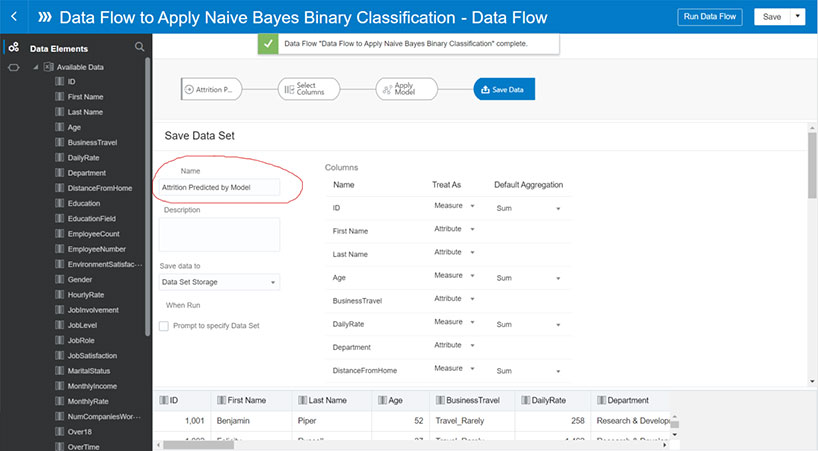
After successful completion of the data flow we will have a new data set with a column for predicted attrition. We can then open this new dataset and create a Data Visualization project to analyze the results.
Step 11: Use Data Visualization to Analyze the Predicted Attrition Results
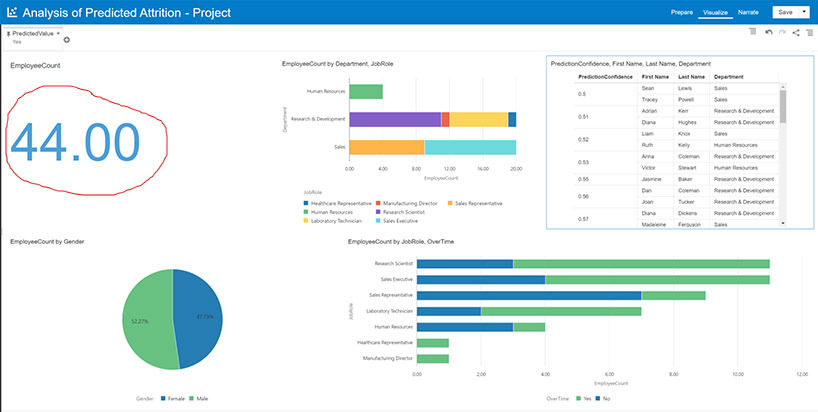
There are many great ways to analyze and present data using machine learning and predictive analytics. This post only scratched the surface. I encourage you to experiment with the machine learning capabilities of Oracle Analytics Cloud.
I also invite you to check-out our Oracle Analytics Cloud Service and let us show you how we can, with our experience and pre-built templates, implement a complete solution in 4 to 6 weeks.
